1. w./w.o. non-face reg loss
We can see that with the non-face reg loss, the rendered head is more temporal stable and realistic.
Generating talking person portraits given arbitrary speech input is a crucial problem in the field of digital humans. A modern talking face generation system is expected to achieve the goals of generalized audio-lip synchronization, good video quality, and high system efficiency. Recently, the neural radiance field (NeRF) has become a popular rendering technique in this field since it can achieve high-fidelity and 3D-consistent talking face generation with a few-minute-long training video. However, the NeRF-based methods are challenged with non-generalized lip motion prediction, non-robust rendering results to OOD motion, and low inference efficiency. In this paper, we propose GeneFace++ to handle these challenges by 1) designing a generic audio-to-motion model that utilizes pitch and talking style information to improve temporal consistency and lip accuracy; 2) introducing a landmark locally linear embedding method to post-process the predicted motion sequence to alleviate the visual artifact; 3) proposing an instant motion-to-video renderer to achieve efficient training and real-time inference. With these settings, GeneFace++ becomes the first NeRF-based method that achieves stable and real-time talking face generation with generalized audio-lip synchronization. Extensive experiments show that our method outperforms state-of-the-art baselines in terms of subjective and objective evaluation.
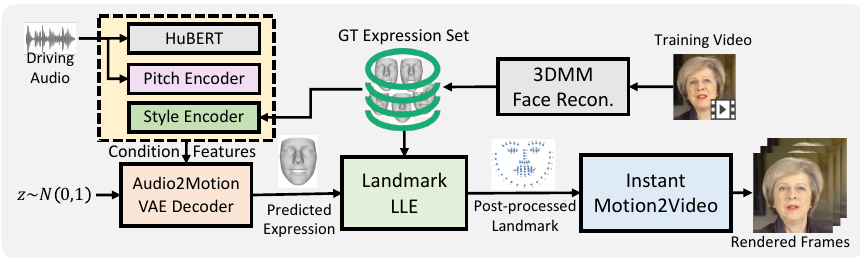
We provide a demo video in which our GeneFace++ of 2 identities (May and Obama) are driven by audio clips from 6 languages (English, Chinese, French, German, Korean, and Japanese), to show that we achieve the three goals of modern talking face system:
To further show the good lip-sync generalizability of GeneFace++, in the following video, we provide a hard case, in which all methods are driven by a three-minute-long song.
We can see that with the non-face reg loss, the rendered head is more temporal stable and realistic.
Click the image below to open a html that could control a slider to compare two images:
